 Disclaimer: the last one is ours!
Disclaimer: the last one is ours!curlsNow that PhantomJS’ development has stopped, Headless Chrome is in the spotlight — and people love it, including us. At PhantomBuster, scraping is a huge part of what we do, and we use Headless Chrome extensively.
In this blog post, I will give you a quick tour of the Headless Chrome ecosystem and show you what we’ve learned after having scraped millions of pages.
Headless Chrome is basically PhantomJS, but made by Google’s Chrome team. They say they are committed to the project and will maintain it for the foreseeable future.
It means that we can now harvest the speed and power of Chrome for all our scraping and automation needs, with the features that come bundled with the most used browser in the world: support of all websites, fast and modern JS engine and the great DevTools API. Awesome! 👌
Disclaimer: the last one is ours!
I don’t know if you’ve heard, but there are a lot of NodeJS libraries for exploiting Chrome’s new --headless mode. Each one has its specificity, and we’ve just added our own to the mix, NickJS. How could we feel at ease claiming we’re scraping experts without having our very own scraping library 😉
There is even a C++ API and the community is releasing libraries in other languages, like this one in Go. That said, we recommend using a NodeJS tool as it’s the same language as what’s interpreted in the pages (you’ll see below how that can come handy).
We don’t really want to stir this endless debate, but less than two weeks ago LinkedIn was ordered by a US District Judge to allow scraping of public profiles. As of now, it’s only a preliminary injunction and the lawsuit still has to take place. LinkedIn will fight this for sure, but you can rest assured that we’ll monitor the situation with close attention. It’s interesting because we talk a lot about LinkedIn in this article.
Anyway, this is a technical article, so we won’t delve into the legality question of particular scraping practices. In any case, you should always strive to respect the target website’s ToS. We’re not responsible for any damages caused by what you’ll learn in this article 😉
Listed below are some tips & tricks used almost daily at PhantomBuster. The code examples are using our own scraping library but they’re easy to rewrite for any other Headless Chrome tool. We’re really more interested in sharing the concepts here.
Scraping with a full-featured browser gives you peace of mind. No need to worry about CORS, sessions, cookies, CSRF and other modern web stuff. Just simulate a human and you’re in.
But sometimes login forms are so hardened that restoring a previously saved session cookie is the only solution to get in. Some sites will send emails or text messages with codes when they feel something is off. We don’t have time for that. Just open the page with your session cookie already set.
⤵️ Bypassing the LinkedIn login form by setting a cookie. GitHub Gist
await nick.setCookie({
name: "li_at",
value: "a session cookie value copied from your DevTools",
domain: "www.linkedin.com"
})
A famous example of that is LinkedIn. Setting the li_at cookie will guarantee your scraper bot access to their social network (please note: we encourage you to respect your target website ToS).
We believe websites like LinkedIn can’t afford to block a real-looking browser with a valid session cookie. It’s too risky for them as false-positives would trigger too many support requests from angry users!
If there’s one important thing we’ve learned, it’s this one. Extracting data from a page with jQuery is very easy. In retrospect, it’s obvious. Websites give you a highly structured, queryable tree of data-containing elements (it’s called the DOM) — and jQuery is a very efficient DOM query library. So why not use it to scrape? This “trick” has never failed us.
A lot of sites already come with jQuery so you just have to evaluate a few lines in the page to get your data. If that’s not the case, it’s easy to inject it:
⤵️ Scraping the Hacker News homepage with jQuery (yes, we know they have an API). GitHub Gist
await tab.open("news.ycombinator.com")
await tab.untilVisible("#hnmain") // Make sure we have loaded the page
await tab.inject("https://code.jquery.com/jquery-3.2.1.min.js") // We're going to use jQuery to scrape
const hackerNewsLinks = await tab.evaluate((arg, callback) => {
// Here we're in the page context. It's like being in your browser's inspector tool
const data = []
$(".athing").each((index, element) => {
data.push({
title: $(element).find(".storylink").text(),
url: $(element).find(".storylink").attr("href")
})
})
callback(null, data)
})
 Screenshot from anti-captcha.com (they’re not kidding 😀)
Screenshot from anti-captcha.com (they’re not kidding 😀)
The answer is CAPTCHA solving services1. You can buy them by the thousands for a few dollars and it generally takes less than 30 seconds per CAPTCHA. Keep in mind that it’s usually more expensive during their night time as there are fewer humans available.
A simple Google search will give you multiple choices of APIs for solving any type of CAPTCHA, including the latest reCAPTCHAs from Google ($2 per 1000).
Hooking your scraper code to these services is as easy as making an HTTP request. Congratulations, your bot is now a human!
On our platform, we make it easy for our users to solve CAPTCHAs should they require it. Our buster library can make calls to multiple solving services:
⤵️ Handling a CAPTCHA problem like it’s nothing. GitHub Gist
if (await tab.isVisible(".captchaImage")) {
// Get the URL of the generated CAPTCHA image
// Note that we could also get its base64-encoded value and solve it too
const captchaImageLink = await tab.evaluate((arg, callback) => {
callback(null, $(".captchaImage").attr("src"))
})
// Make a call to a CAPTCHA solving service
const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink)
// Fill the form with our solution
await tab.fill(".captchaForm", { "captcha-answer": captchaAnswer }, { submit: true })
}
We often see scraping beginners make their bot wait for 5 or 10 seconds after having opened a page or clicked a button — they want to be sure the action they did has had time to have an effect.
But that’s not how it should be done. Our 3 steps theory applies to any scraping scenario: you should wait for the specific DOM elements you want to manipulate next. It’s faster, clearer and you’ll get more accurate errors if something goes wrong:
await tab.open("https://www.facebook.com/phbuster/posts/676836339178597")
// await Promise.delay(5000) // DON'T DO THIS!
await tab.waitUntilVisible(".permalinkPost .UFILikeLink")
// You can now safely click the "Like" button...
await tab.click(".permalinkPost .UFILikeLink")
It’s true that in some cases it might be necessary to fake human delays. A simple await Promise.delay(2000 + Math.random() * 3000) will do the trick.
We’ve found MongoDB to be a good fit for most of our scraping jobs. It has a great JS API and the Mongoose ORM is handy. Considering that when you’re using Headless Chrome you’re already in a NodeJS environment, why do without it?
Sometimes scraping is not about making sense of the DOM but more about finding the right “export” button. Remembering this has saved us a lot of time on multiple occasions.
Kidding aside, some sites will be easier than others. Let’s take Macys.com as an example. All of their product pages come with the product’s data in JSON-LD form directly present in the DOM. Seriously, go to any of their product page and run: JSON.parse(document.querySelector("#productSEOData").innerText) or JSON.parse(document.querySelector("script[data-bootstrap='feature/product']").innerText). You’ll get a nice object ready to be inserted into MongoDB. No real scraping necessary!
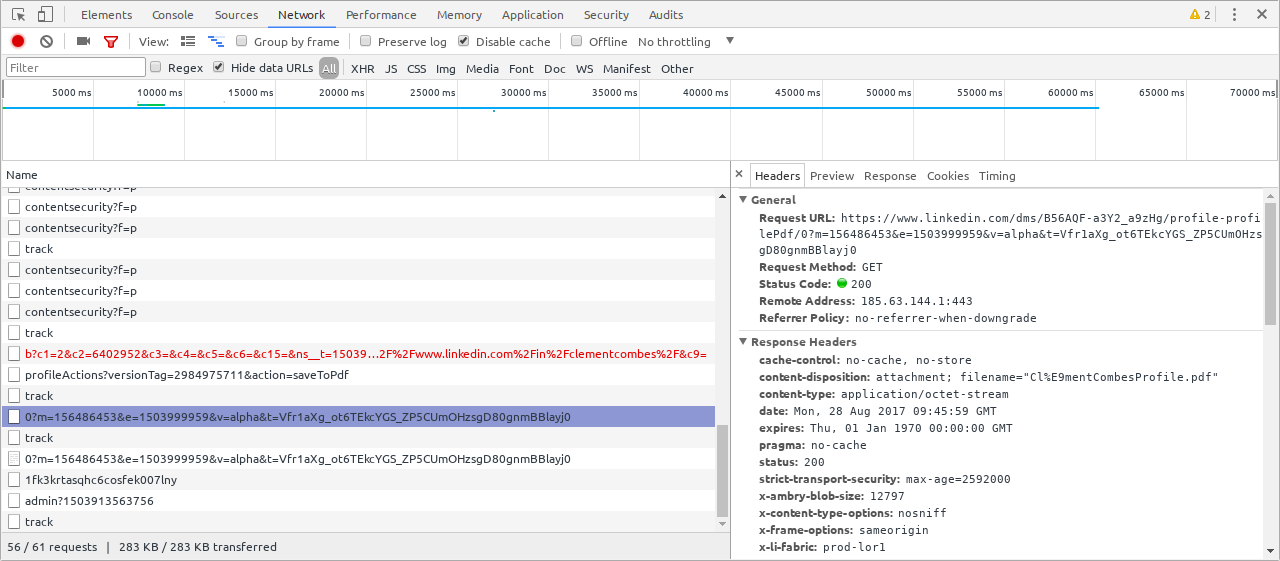
Because we’re using the DevTools API, the code we write has the equivalent power of a human using Chrome’s DevTools. That means your bot can intercept, examine and even modify or abort any network request.
We tested this by downloading a PDF CV export from LinkedIn. Clicking the “Save to PDF” button from a profile triggers an XHR in which the response content is a PDF file. Here’s one way of intercepting the file and writing it to disk:
⤵️ Here tab is a NickJS tab instance from which we get the Chrome Remote Interface API. GitHub Gist
let cvRequestId = null
tab.driver.client.Network.responseReceived((e) => {
if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/") > 0) {
cvRequestId = e.requestId
}
})
tab.driver.client.Network.loadingFinished((e) => {
if (e.requestId === cvRequestId) {
tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {
require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.base64Encoded ? 'base64' : 'utf8')))
})
}
})
By the way, the DevTools protocol is evolving rapidly. There’s now a way to set how and where the incoming files are downloaded with Page.setDownloadBehavior(). We have yet to test it but it looks promising!
⤵️ Example of an extremely aggressive request filter. The blacklist further blocks requests that passed the whitelist. GitHub Gist
const nick = new Nick({
loadImages: false,
whitelist: [
/.*\.aspx/,
/.*axd.*/,
/.*\.html.*/,
/.*\.js.*/
],
blacklist: [
/.*fsispin360\.js/,
/.*fsitouchzoom\.js/,
/.*\.ashx.*/,
/.*google.*/
]
})
In the same vein, we can speed up our scraping by blocking unnecessary requests. Analytics, ads and images are typical targets. However, you have to keep in mind that it will make your bot less human-like (for example LinkedIn will not serve their pages properly if you block all images — we’re not sure if it’s deliberate or not).
In NickJS, we let the user specify a whitelist and a blacklist populated with regular expressions or strings. The whitelist is particularly powerful but can easily break your target website if you’re not careful.
The DevTools protocol also has Network.setBlockedURLs() which takes an array of strings with wildcards as input.
What’s more, new versions of Chrome will come with Google’s own built-in "ad-blocker" — it’s more like an ad “filter” really. The protocol already has an endpoint called Page.setAdBlockingEnabled() for it (we haven’t tested it yet).
That’s it for our tips & tricks! 🙏
Recently an article was published listing multiple ways to detect Headless Chrome visitors. It was also possible with PhantomJS. Both of these describe techniques that range from basic User-Agent string comparison to more complex stuff like triggering errors and inspecting the stack trace.
This is basically a big cat-and-mouse game between angry sys-admins and ingenious bot makers… But you know what? We’ve never seen these methods implemented in the wild. Yes, it is technically possible to detect automated visitors. But who’s going to be willing to face potential false-positives? This is especially risky for large audience websites.
If you know of websites that have these detection features running in production, we’d love to hear from you! 😃
We believe scraping has never been so easy. With the latest tools at our disposal and the know-how, it can even become a pleasant and fun activity for us developers.
By the way, this Franciskim.co “I Don’t Need No Stinking API” article inspired our post. Thanks! Also, check out this repo for detailed instructions on how to get started with Puppeteer.
In the next article, I’ll write about “bot mitigation” companies like Distill Networks and the wonderful world of HTTP proxies and IP address allocations.
What next? Check out our library at NickJS.org, our scraping & automation platform at PhantomBuster.com. You might also be interested in our theory of the 3 scraping steps.
It’s a joke. I have to say it otherwise I receive emails… ↩